Visualization of bird sound files (spectral)¶
In [1]:
from lib.File import File
from matplotlib import pyplot as plt
from data.loader import get_kasios_obs, get_obs, map_path
import numpy as np
from math import sqrt
import pandas as pd
Utilities¶
In [2]:
def get_spectrums(df):
###
### Generate the spectres for all files within the dataframe given (maintains the df index)
###
N = df.shape[0]
data = {} # Initialisation
for i, (index, row) in enumerate(df.iterrows()):
# Progression
if i % 50 == 0:
print("Computing spectrums... ({0:.0%}) ".format(i/N), end="\r")
# Reading the file
f = File(row["song"])
spectre, freq = f.getNormalizedSpectre()
if spectre is None:
# Sometimes the spectre cannot be compute because there is too much noise
continue
# Adding the spectre
data[index] = spectre
# Building output dataframe
X = pd.DataFrame.from_dict(data, columns = freq, orient = "index")
X = X.reindex(df.index, fill_value = 0)
print("All spectrums have been generated. ")
return X
def merge_spectres(spectres):
###
### Merge multiple spectres to one and normalize it.
###
m_spectres = spectres.sum(axis = 0)
m_spectres = (m_spectres - m_spectres.mean())/m_spectres.std()
return m_spectres
# Plot only one species
def plot_species(species, spectres, df):
# Parameter for the species
species_spectres = spectres.loc[df.English_name == species]
species_color = df.loc[df.English_name == species].color.iloc[0]
plt.title(species)
plt.plot(merge_spectres(species_spectres), color = species_color) # Merge all spectres together
plt.xlabel("Fréquence (Hz)")
Load files and compute all spectrums¶
In [3]:
# Loads files and makes conversion if necessary
df_all = get_obs(songs = True)
df_kasios = get_kasios_obs(songs = True)
In [4]:
# X = get_spectrums(df_all) # Can be very long
# X.to_pickle("data/all_birds_freq.pickle") # Save to cache
X = pd.read_pickle("data/all_birds_freq.pickle") # Quicker to use cache ;)
X.head()
Out[4]:
In [5]:
#X_kasios = get_spectres(df_kasios) # Can be very long
#X_kasios.to_pickle("data/kasios_birds_freq.pickle")
X_kasios = pd.read_pickle("data/kasios_birds_freq.pickle") # Quicker to use cache ;)
X_kasios.head()
Out[5]:
In [6]:
df_all.English_name.unique()
Out[6]:
Blue pipit analysis¶
Average spectrum¶
In [7]:
species = df_all.English_name.unique()
plt.figure(figsize=(15,15))
plt.suptitle('Average spectrum of species', fontsize=25)
for i, specie in enumerate(species):
plt.subplot(5,4,i+1)
plot_species(specie, X, df_all)
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
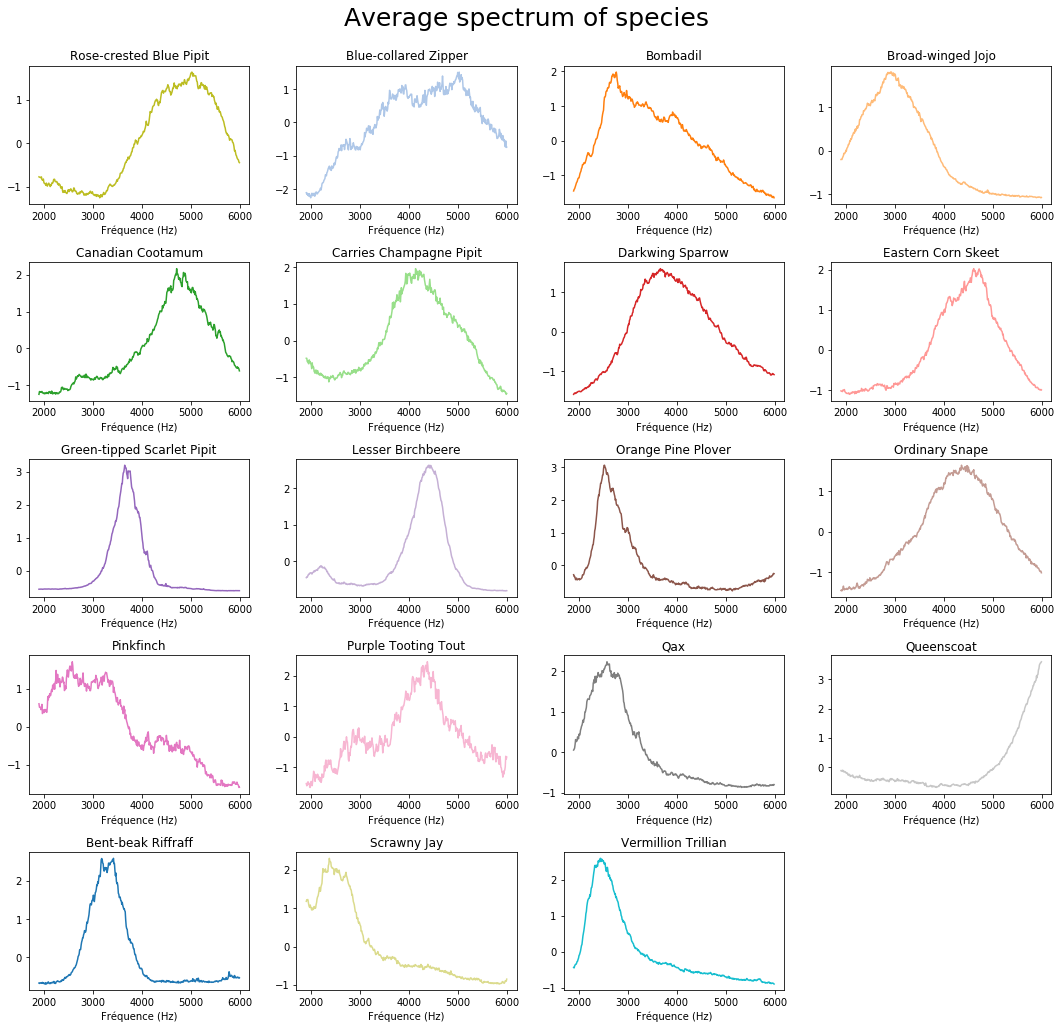
You can see that frequencies are mainly between 3500Hz and 6000Hz for the Blue Pipit, with also some at 2000Hz.
Sometimes you get some aberation due to bad noise filtration.
In [8]:
N = 6
X_blue = X.loc[(df_all.English_name == "Rose-crested Blue Pipit")
& (df_all['Vocalization_type'] == 'song')].sample(N)
df_blue = df_all.loc[X_blue.index]
flim = 4000
plt.figure(figsize=(15,10))
plt.suptitle('Random Blue Pipit "song" spectrums', fontsize=22)
for i in range(N):
obs = df_blue.iloc[i]
plt.subplot(3, 2, i+1)
plt.plot(X_blue.iloc[i])
plt.axvline(flim, color="red")
plt.title("{} n°{}".format(obs.English_name, obs.name))
plt.show()
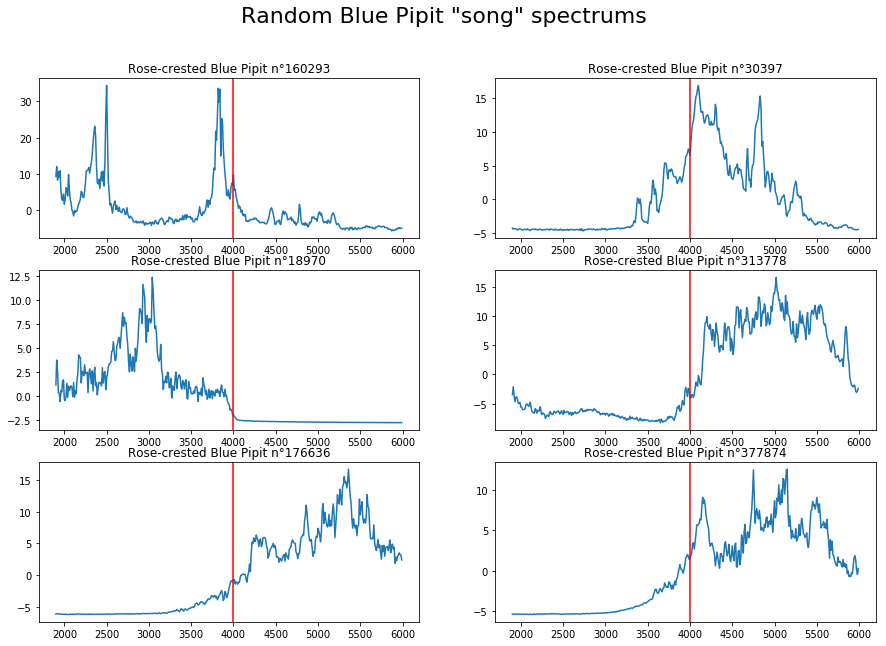
For the "calls"¶
In [9]:
N = 6
X_blue = X.loc[(df_all.English_name == "Rose-crested Blue Pipit")
& (df_all['Vocalization_type'] == 'call')].sample(N)
df_blue = df_all.loc[X_blue.index]
flim = 4000
plt.figure(figsize=(15,10))
plt.suptitle('Random Blue Pipit "call" spectrums', fontsize=22)
for i in range(N):
obs = df_blue.iloc[i]
plt.subplot(3, 2, i+1)
plt.plot(X_blue.iloc[i])
plt.axvline(flim, color="red")
plt.title("{} n°{}".format(obs.English_name, obs.name))
plt.show()
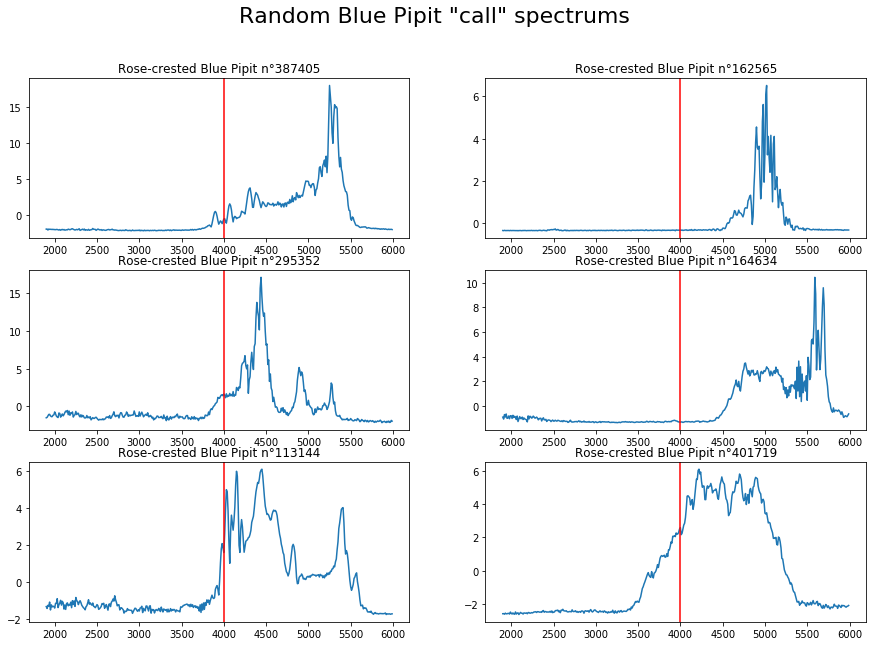
Kasios files¶
In [10]:
plt.figure(figsize=(15,40))
for i in range(X_kasios.shape[0]):
plt.subplot(10,2,i+1)
plt.plot(X_kasios.iloc[i])
plt.title("Kasios n°{}".format(i+1))
plt.axvline(flim, color="red")
plt.show()
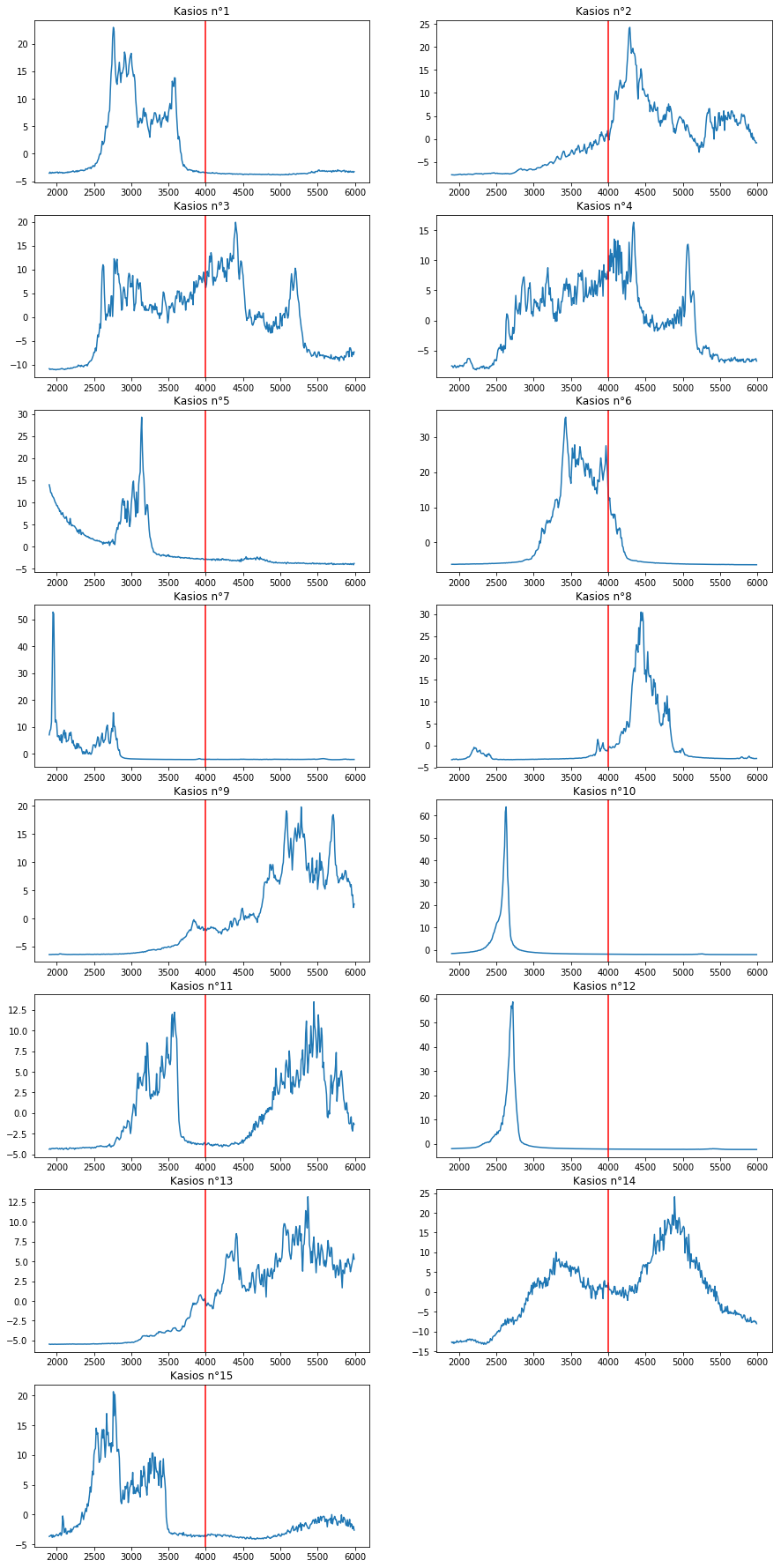
You can see that some Kasios file does not contains the Blue Pipit frequencies and even contains foreign frequencies for this species. Then, you can eliminate 1, 3, 4, 5, 6, 7, 10, 11, 12, 14 and 15 that contains foreign frequencies.
The Blue Pipit must be within 2, 8, 9 and 13. We might also include 11 and 14.
Analyse a specific file¶
In [11]:
obs_id = 160293
obs = df_all.loc[obs_id]
f = File(obs.song)
In [12]:
plt.plot(f.data)
Out[12]:
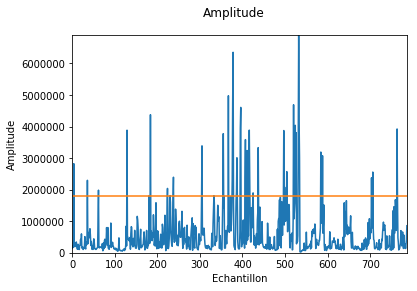
In [13]:
f.plotAmp()
Out[13]:
In [14]:
spectre, freq = f.getNormalizedSpectre()
plt.plot(freq, spectre)
Out[14]: